GPU Computing – What Is It?
Do you keep hearing about GPU computing or acceleration, but are not sure what they mean? Here's everything you need to know.
GPU or Graphics Processing Units are present in all electronic circuits that produce one form of display or the other, especially the computer.
Early graphics processors were relatively simple. But with the advent of gaming, 3D animation, and video rendering tasks that pushed CPUs beyond their limits, more powerful GPUs had to come to the rescue.
These new GPU cards grew in power and complexity over time, with different companies and researchers seeking out ways to leverage their parallel execution advantage. This post shows you how it’s been going so far.
Table of Contents
hide
What Is A GPU?
A GPU or Graphics Processing Unit is a specialized circuit designed for the manipulation of data to aid in the creation of images for display. In other words, a GPU is a system that creates the images you see on any display surface, such as the computer monitor, smartphone screen, game consoles, and so on.
GPUs were initially straightforward devices that put graphic elements together to create an ideal output for a specific device. Over time, however, and with the advent of computer gaming, GPUs started to grow in complexity and power, giving birth to GPGPU or General Purpose Computing on GPUs.
What Is GPU Computing?
GPU computing or GPGPU is the use of a GPU for computation beyond graphics. This means using the GPUs embedded in a computer’s video card and originally intended for processing computer graphics for the computation of other types of data, such as scientific simulations, cryptocurrency mining, algebra computations, weather forecasting, neural networks, and so on.
The reason for this evolution of GPU computing comes from the impressive development of graphics processing units, which comes from the distributed parallel architecture of modern GPU systems.
As the computer’s CPU grew more powerful and could handle more complex programs and games, video card makers also tried to keep up with the developments in modern computing and 3D graphics. Nvidia unveiled the GeForce 256 in 1999 as the world’s first GPU video card and things evolved from there.
The major advantage of GPU cards over CPUs is their parallel processing architecture, which makes them able to process large data tasks in a distributed, parallel manner that prevents bottlenecks and CPU freezes.
What Are The Applications For GPU Computing?
The applications of GPU computing are many, here is a look at some top uses:
- Machine learning & neural networks
- Fuzzy logic
- Bio-informatics
- Molecular modeling
- Video rendering
- Geometric computing
- Climate Research and weather forecasting
- Astrophysics
- Cryptography
- Computer vision
- Password cracking
- Quantum research
GPU Vs CPU Processing
GPUs and CPUs both process digital data, but they do it in different ways. The CPU or central processing unit is designed for serial processing at high speeds, while GPUs are designed for parallel processing at much lower speeds. Of course, a CPU can use hyper-threading to get 2 threads per core, or even have dozens of cores, but they are fundamentally serial processors.
While CPUs can have a few cores, modern GPUs come with thousands of cores, for instance, the Nvidia GeForce RTX 3090 which features 10K+ cores. To get an advantage over CPUs though, the data has to be capable of parallel processing, such as processing a stream containing thousands of images at a go.
GPUs Vs ASICs
ASIC stands for Application Specific Integrated Circuit and this means that it can only perform one task – that is, the task it was designed to perform. An ASIC is a unique machine that is developed from scratch and requires expert hardware knowledge to build. ASICs are commonly used in cryptocurrency mining, as they offer good parallel processing benefits and better efficiency than GPUs.
The major difference between the two, however, is that GPUs are more versatile. For instance, you can easily build a cryptocurrency mining rig using GPUs. The parts are easily available and if you are done with mining, you can always sell the GPU card to gamers or other miners. With ASICs however, you can only sell a used machine to other miners, because you can hardly do anything else with it.
Beyond cryptocurrency mining, it becomes even more difficult to lay your hands on an ASIC machine, because they are not mass products. This contrasts strongly with GPU systems that you can get everywhere and easily configure.
GPU Vs Cluster Computing
While a single GPU card contains thousands of cores, which add tremendous power to any computer you attach it to, you can theoretically add as many GPU cards to the computer mainboard as it can handle, and further increase its processing capability.
A computer cluster, on the other hand, refers to multiple computers that are networked together to function as one big computer – a supercomputer. Each computer on the network is called a node and can have a multi-core CPU, as well as one or more GPU cards on board.
Each cluster must have a master node, which is the front computer that is responsible for managing and scheduling its worker nodes. It will also contain software that allocates data and programs for its worker nodes to compute and return results.
GPU Acceleration Vs Hyper-threading
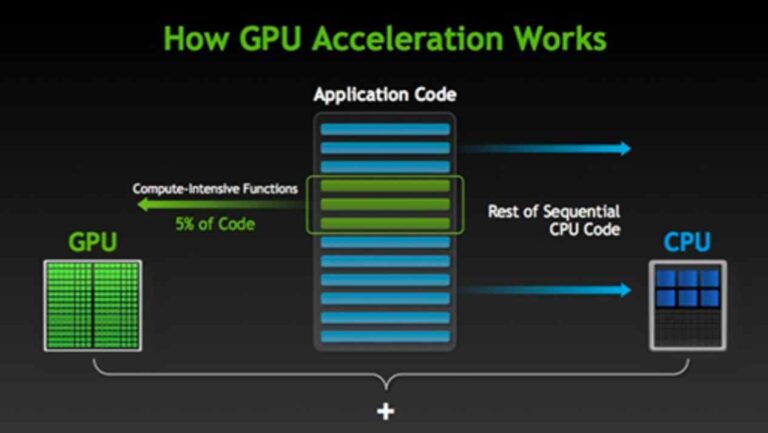
The CPU is designed to handle multiple tasks at once, and that’s why it runs at very high speeds, scheduling processing time between those multiple processes. However, when it encounters a compute-intensive function, then it might spend a while in the loop before it returns to the other processes. This usually results in a general slow-down of the computer, and worse cases, a complete freeze of the system.
Computer designers can avoid this dreaded scenario by either using hyper-threading or GPU acceleration. Hyper-threading allows a single CPU core to function as two processing threads. So, when one thread is trapped in a compute-intensive loop, the other thread can still hold the system together.
Modern computers now have multiple cores from 2 to 4, 8, 16, 32, and so on. Plus, they feature hyper-threading, so a 2-core CPU offers 4 threads, a 4-core offers 8 threads, and so on.
Hyper-threading with multi-core CPUs will solve most computing problems, prevent bottlenecks, and deliver top performance with simple games, music production, and small graphics, video, and machine learning projects. But when you need more power than that, then a GPU is often the right solution.
GPU or hardware acceleration is the ability of a software application to leverage a GPUs parallel processing power to crunch large numbers of data, without bogging down the CPU. Many professional applications depend on GPU acceleration to function well. These include video and animation design/rendering programs, encoders, cryptography, large neural networks, and so on.
GPGPU Programming Basics
General purpose programming of GPUs was initially done using DirectX and OpenGL libraries. These were designed strictly for graphics development, however, so you had to re-purpose your data into graphic-like models to work.
Luckily, there have been major advancements in GPGPU over the years, leading to libraries, programming languages, and frameworks. The most popular of these frameworks is CUDA from Nvidia.
CUDA makes it easy for any developer to dive into GPU programming without needing to know the nitty-gritty of classic GPU programming. It provides features that enhance development beyond graphics, with many units even featuring machine-learning-specific functions.
Available libraries also make it easy to create new GPU-accelerated programs from scratch or to adapt pre-written ones to parallel processing. You choose the right library, optimize your code for parallel loops, recompile, and that’s it.
CUDA Cores Vs Stream Processors
Often, you will come across the terms Cuda cores and stream processors. Both terms simply refer to the GPU core or Arithmetic Logic Units of a GPU. CUDA Core is a proprietary technology from Nvidia, while Stream processors are from AMD.
Another term you may come across is Streaming Multi-Processor or SM. This is another Nvidia technology that originally grouped 8 CUDA cores per SM. It executes 32-thread warps at a go, using 4 clock cycles per command. Newer designs now feature over 100 cores per streaming multi-processor.
Top GPU Languages & Libraries
There are so many libraries and languages out there that work on both Nvidia CUDA and AMD platforms. Following are just a few:
- Nvidia cuBLAS – Basic linear algebra subprograms for CUDA
- cuDNN – Deep neural networks library
- OpenCL – Open standard for parallel programming
- OpenMP – For AMD GPUs
- HIP – C++ library
- Nvidia cuRAND – Random number generation
- cuFFT – For Fast Fourier transform
- Nvidia NPP – 2D image and signal processing
- GPU VSIPL – Vector image and signal processing
- OpenCV – GPU library for computer vision
- OpenACC – Language for parallel development
- PyCUDA – Python for CUDA platform
- TensorRT – Deep learning for CUDA
- CUDA C++ – C++ language for CUDA
- CUDA C – C language for CUDA
- CUDA Fortran – CUDA for FORTRAN developers
Top GPU Cluster Projects
As of June 2022, 8 of the 10 fastest supercomputers in the world are GPU-accelerated. They all share the Linux OS as well, and are as follows:
| Rank | Name | Petaflops | CPU Cores | GPU Cores | Power (kW) | Year |
| 1. | Frontier | 1,102 | 591,872 | 8,138,240 | 21,100 | 2022 |
| 2. | LUMI | 151.90 | 75,264 | 1,034,880 | 2,900 | 2022 |
| 3. | Summit | 148.6 | 202,752 | 2,211,840 | 10,096 | 2018 |
| 4. | Sierra | 94.64 | 190,080 | 1,382,400 | 7,438 | 2018 |
| 5. | Perlmutter | 64.59 | N/A | N/A | 2,589 | 2021 |
| 6. | Selene | 63.46 | 71,680 | 483,840 | 2,646 | 2020 |
| 7. | Tianhe-2 | 61.445 | 427,008 | 4,554,752 | 18,482 | 2013 |
| 8. | Adastra | 46.1 | 21,632 | 297,440 | 921 | 2022 |
Conclusion
Reaching the end of this dive into GPU computing and all that comes with it, you should have gotten an idea of its power and scope by now.
For further information, you can check out the developer platform of Nvidia here or that of AMD here.

Related Articles