Calcul GPU - Qu'est-ce que c'est ?
Vous entendez sans cesse parler de calcul GPU ou d'accélération, mais vous n'êtes pas sûr de ce que cela signifie ? Voici tout ce que vous devez savoir.
Les GPU ou Graphics Processing Units sont présents dans tous les circuits électroniques qui produisent une forme d'affichage ou l'autre, en particulier l'ordinateur.
Les premiers processeurs graphiques étaient relativement simples. Mais avec l'avènement des tâches de jeu, d'animation 3D et de rendu vidéo qui ont poussé les processeurs au-delà de leurs limites, des GPU plus puissants ont dû venir à la rescousse.
Ces nouvelles cartes GPU ont gagné en puissance et en complexité au fil du temps, différentes entreprises et chercheurs cherchant des moyens de tirer parti de leur avantage en matière d'exécution parallèle. Cet article vous montre comment cela se passe jusqu'à présent.
Table des Matières
cacher
Qu'est-ce qu'un GPU ?
Un GPU ou Graphics Processing Unit est un circuit spécialisé conçu pour la manipulation de données afin d'aider à la création d'images à afficher. En d'autres termes, un GPU est un système qui crée les images que vous voyez sur n'importe quelle surface d'affichage, comme l'écran de l'ordinateur, l'écran du smartphone, les consoles de jeux, etc.
Les GPU étaient initialement des appareils simples qui assemblaient des éléments graphiques pour créer une sortie idéale pour un appareil spécifique. Au fil du temps, cependant, et avec l'avènement des jeux informatiques, les GPU ont commencé à gagner en complexité et en puissance, donnant naissance à GPGPU ou General Purpose Computing sur GPU.
Qu'est-ce que le calcul GPU ?
Le calcul GPU ou GPGPU est l'utilisation d'un GPU pour le calcul au-delà des graphiques. Cela signifie utiliser les GPU intégrés dans la carte vidéo d'un ordinateur et destinés à l'origine au traitement des graphiques informatiques pour le calcul d'autres types de données, telles que les simulations scientifiques, l'extraction de crypto-monnaie, les calculs d'algèbre, les prévisions météorologiques, les réseaux de neurones, etc.
La raison de cette évolution de l'informatique GPU vient du développement impressionnant des unités de traitement graphique, qui provient de l'architecture parallèle distribuée des systèmes GPU modernes.
Au fur et à mesure que le processeur de l'ordinateur devenait plus puissant et pouvait gérer des programmes et des jeux plus complexes, les fabricants de cartes vidéo ont également essayé de suivre les développements de l'informatique moderne et des graphiques 3D. Nvidia a dévoilé le GeForce 256 en 1999 en tant que première carte vidéo GPU au monde et les choses ont évolué à partir de là.
Le principal avantage des cartes GPU par rapport aux processeurs est leur architecture de traitement parallèle, qui les rend capables de traiter des tâches de données volumineuses de manière distribuée et parallèle, ce qui évite les goulots d'étranglement et les blocages du processeur.
Quelles sont les applications du GPU Computing ?
Les applications de l'informatique GPU sont nombreuses, voici un aperçu de quelques utilisations principales :
- Apprentissage automatique et réseaux de neurones
- Logique floue
- Bio-informatique
- Modélisation moléculaire
- Rendu vidéo
- Calcul géométrique
- Recherche climatique et prévisions météorologiques
- Astrophysique
- Cryptographie
- Vision par ordinateur
- Cracking de mot de passe
- Recherche quantique
Traitement GPU vs CPU
Les GPU et les CPU traitent tous les deux les données numériques, mais ils le font de différentes manières. Le CPU ou l'unité centrale de traitement est conçu pour le traitement en série à des vitesses élevées, tandis que les GPU sont conçus pour le traitement en parallèle à des vitesses beaucoup plus faibles. Bien sûr, un processeur peut utiliser l'hyper-threading pour obtenir 2 threads par cœur, ou même avoir des dizaines de cœurs, mais ce sont fondamentalement des processeurs série.
Alors que les processeurs peuvent avoir quelques cœurs, les GPU modernes sont livrés avec des milliers de cœurs, par exemple, le Nvidia GeForce RTX 3090 qui comporte plus de 10 XNUMX cœurs. Cependant, pour obtenir un avantage sur les processeurs, les données doivent pouvoir être traitées en parallèle, comme le traitement d'un flux contenant des milliers d'images à la fois.
GPU contre ASIC
ASIC signifie Application Specific Integrated Circuit, ce qui signifie qu'il ne peut effectuer qu'une seule tâche, c'est-à-dire la tâche pour laquelle il a été conçu. Un ASIC est une machine unique qui est développée à partir de rien et dont la construction nécessite une connaissance approfondie du matériel. Les ASIC sont couramment utilisés dans l'extraction de crypto-monnaie, car ils offrent de bons avantages de traitement parallèle et une meilleure efficacité que les GPU.
La principale différence entre les deux, cependant, est que les GPU sont plus polyvalents. Par exemple, vous pouvez facilement créer une plate-forme d'extraction de crypto-monnaie à l'aide de GPU. Les pièces sont facilement disponibles et si vous en avez fini avec l'exploitation minière, vous pouvez toujours vendre la carte GPU aux joueurs ou à d'autres mineurs. Cependant, avec les ASIC, vous ne pouvez vendre une machine d'occasion qu'à d'autres mineurs, car vous ne pouvez pratiquement rien faire d'autre avec.
Au-delà du minage de cryptomonnaies, il devient encore plus difficile de mettre la main sur une machine ASIC, car ce ne sont pas des produits de masse. Cela contraste fortement avec les systèmes GPU que vous pouvez obtenir partout et facilement configurer.
GPU vs Cluster Computing
Alors qu'une seule carte GPU contient des milliers de cœurs, ce qui ajoute une puissance énorme à n'importe quel ordinateur auquel vous la connectez, vous pouvez théoriquement ajouter autant de cartes GPU à la carte mère de l'ordinateur qu'elle peut en gérer, et augmenter encore sa capacité de traitement.
Un cluster d'ordinateurs, d'autre part, fait référence à plusieurs ordinateurs qui sont mis en réseau pour fonctionner comme un seul gros ordinateur - un superordinateur. Chaque ordinateur du réseau est appelé un nœud et peut avoir un processeur multicœur, ainsi qu'une ou plusieurs cartes GPU intégrées.
Chaque cluster doit avoir un nœud maître, qui est l'ordinateur frontal responsable de la gestion et de la planification de ses nœuds de travail. Il contiendra également un logiciel qui alloue des données et des programmes à ses nœuds de travail pour calculer et renvoyer des résultats.
Accélération GPU Vs Hyper-threading
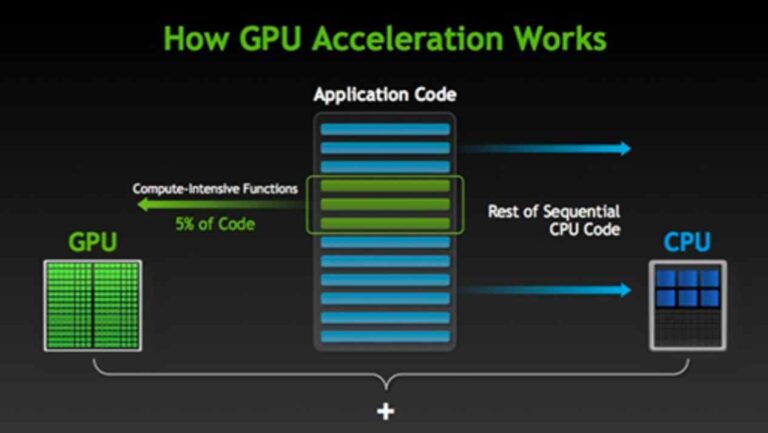
Le processeur est conçu pour gérer plusieurs tâches à la fois, et c'est pourquoi il fonctionne à des vitesses très élevées, en planifiant le temps de traitement entre ces multiples processus. Cependant, lorsqu'il rencontre une fonction à forte intensité de calcul, il peut passer un certain temps dans la boucle avant de revenir aux autres processus. Cela se traduit généralement par un ralentissement général de l'ordinateur et, dans le pire des cas, par un gel complet du système.
Les concepteurs d'ordinateurs peuvent éviter ce scénario redouté en utilisant l'hyper-threading ou l'accélération GPU. L'hyper-threading permet à un seul cœur de processeur de fonctionner comme deux threads de traitement. Ainsi, lorsqu'un thread est piégé dans une boucle à forte intensité de calcul, l'autre thread peut toujours maintenir le système ensemble.
Les ordinateurs modernes ont maintenant plusieurs cœurs de 2 à 4, 8, 16, 32, etc. De plus, ils disposent d'un hyper-threading, donc un processeur à 2 cœurs offre 4 threads, un 4 cœurs offre 8 threads, etc.
L'hyper-threading avec des processeurs multicœurs résoudra la plupart des problèmes informatiques, évitera les goulots d'étranglement et offrira des performances optimales avec des jeux simples, la production musicale et de petits projets graphiques, vidéo et d'apprentissage automatique. Mais lorsque vous avez besoin de plus de puissance que cela, un GPU est souvent la bonne solution.
L'accélération GPU ou matérielle est la capacité d'une application logicielle à tirer parti de la puissance de traitement parallèle d'un GPU pour traiter un grand nombre de données, sans enliser le processeur. De nombreuses applications professionnelles dépendent de l'accélération GPU pour bien fonctionner. Il s'agit notamment des programmes de conception/rendu vidéo et d'animation, des encodeurs, de la cryptographie, des grands réseaux de neurones, etc.
Principes de base de la programmation GPGPU
La programmation à usage général des GPU a été initialement effectuée à l'aide de DirectX et OpenGL bibliothèques. Ceux-ci ont été conçus strictement pour le développement graphique, cependant, vous avez dû réutiliser vos données dans des modèles de type graphique pour fonctionner.
Heureusement, il y a eu des avancées majeures dans GPGPU au fil des ans, menant à des bibliothèques, des langages de programmation et des frameworks. Le plus populaire de ces frameworks est CUDA de Nvidia.
CUDA permet à tout développeur de se plonger facilement dans la programmation GPU sans avoir besoin de connaître les moindres détails de la programmation GPU classique. Il fournit des fonctionnalités qui améliorent le développement au-delà des graphiques, avec de nombreuses unités comportant même des fonctions spécifiques à l'apprentissage automatique.
Les bibliothèques disponibles facilitent également la création de nouveaux programmes accélérés par GPU à partir de zéro ou l'adaptation de programmes pré-écrits au traitement parallèle. Vous choisissez la bonne bibliothèque, optimisez votre code pour les boucles parallèles, recompilez, et c'est tout.
CUDA Cores vs processeurs de flux
Souvent, vous rencontrerez les termes Cœurs Cuda et processeurs de flux. Les deux termes font simplement référence au cœur du GPU ou Unités logiques arithmétiques d'un GPU. CUDA Core est une technologie propriétaire de Nvidia, tandis que les processeurs Stream sont d'AMD.
Un autre terme que vous pouvez rencontrer est Streaming Multi-Processor ou SM. Il s'agit d'une autre technologie Nvidia qui regroupait à l'origine 8 cœurs CUDA par SM. Il exécute des chaînes de 32 threads à la fois, en utilisant 4 cycles d'horloge par commande. Les nouvelles conceptions comportent désormais plus de 100 cœurs par multiprocesseur de streaming.
Principaux langages et bibliothèques GPU
Il existe tellement de bibliothèques et de langages qui fonctionnent à la fois sur les plates-formes Nvidia CUDA et AMD. Voici quelques-uns :
- Nvidia cuBLAS – Sous-programmes d'algèbre linéaire de base pour CUDA
- cuDNN – Bibliothèque de réseaux de neurones profonds
- OpenCL – Standard ouvert pour la programmation parallèle
- Openmp – Pour les GPU AMD
- HIP – Bibliothèque C++
- Nvidia cuRAND – Génération de nombres aléatoires
- brassard – Pour la transformée de Fourier rapide
- Centrale nucléaire NVIDIA – Image 2D et traitement du signal
- GPU VSIPL – Image vectorielle et traitement du signal
- OpenCV – Bibliothèque GPU pour la vision par ordinateur
- OuvrirACC – Langage pour le développement parallèle
- PyCUDA – Python pour la plate-forme CUDA
- TensorRT – Apprentissage en profondeur pour CUDA
- CUDAC++ – Langage C++ pour CUDA
- CUDA C – Langage C pour CUDA
- CUDAFortran – CUDA pour les développeurs FORTRAN
Meilleurs projets de cluster GPU
En juin 2022, 8 des 10 supercalculateurs les plus rapides au monde étaient accélérés par GPU. Ils partagent également tous le système d'exploitation Linux et sont les suivants :
| Rang | Nom | Pétaflops | Cœurs de CPU | Cœurs GPU | Puissance (kW) | Année |
| 1. | frontière | 1,102 | 591,872 | 8,138,240 | 21,100 | 2022 |
| 2. | LUMI | 151.90 | 75,264 | 1,034,880 | 2,900 | 2022 |
| 3. | Sommet | 148.6 | 202,752 | 2,211,840 | 10,096 | 2018 |
| 4. | Sierra | 94.64 | 190,080 | 1,382,400 | 7,438 | 2018 |
| 5. | Perlmutter | 64.59 | N/D | N/D | 2,589 | 2021 |
| 6. | Selene | 63.46 | 71,680 | 483,840 | 2,646 | 2020 |
| 7. | Tianhe-2 | 61.445 | 427,008 | 4,554,752 | 18,482 | 2013 |
| 8. | Ad Astra | 46.1 | 21,632 | 297,440 | 921 | 2022 |
Conclusion
Arrivant à la fin de cette plongée dans l'informatique GPU et tout ce qui l'accompagne, vous devriez déjà avoir une idée de sa puissance et de sa portée.
Pour plus d'informations, vous pouvez consulter la plateforme de développement de Nvidia ici ou celle de AMD ici.

Articles Relatifs