Large Language Models: What Are They And How They Work
Looking to understand large language models? Discover their power and applications here. Learn what LLMs are, how they work, and their impact on society and business.

The terms LLM or “Large Language Model” get thrown around more often these days. Most people know they are connected to artificial intelligence, but that’s just it.
Many of today’s powerful artificial intelligence systems – from OpenAI’s ChatGPT to Google’s BERT – are based on large language models, which incidentally, are the source of their power. But what makes these LLMs different from other artificial intelligence technologies before them?
Large language models, as their name suggests, are very large. They are AI systems trained with excessively huge amounts of data, which makes them very efficient with human languages. This post explains how.
Table of Contents
hide
What Are Large Language Models?
Large language models are a type of artificial intelligence system trained to recognize, replicate, predict, and manipulate text or other content. Modern large language models consist of AI neural networks with billions or more parameters and are often trained using petabytes of data.
A large language model can understand lots of things like a human would, although not everything. However, unlike most humans, a large language model can have more extensive knowledge about nearly everything, making it appear like an all-knowing computer.
Large language models today are possible because of the large amount of digital information on the Internet, the lower costs of computing, and the increase in computing power of both CPUs and GPU parallel processors.
How Do Large Language Models Work?
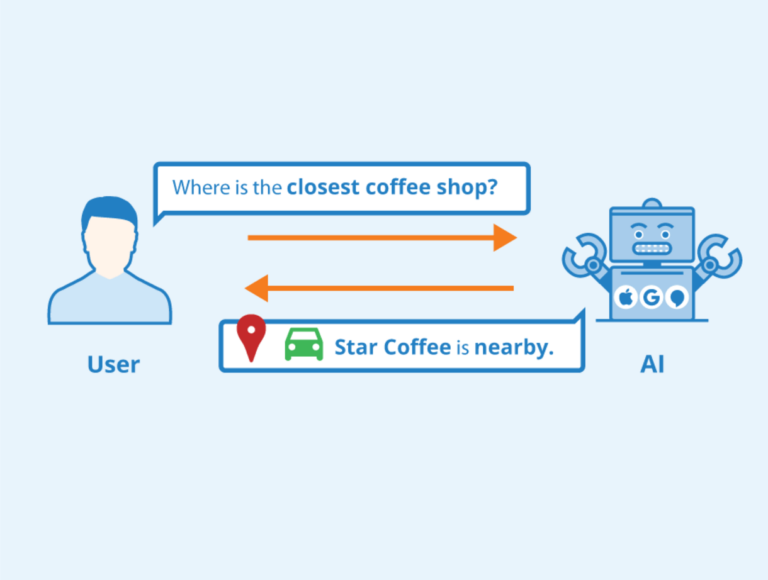
On the surface, a large language model such as ChatGPT is easy to use. All you have to do is type some text and it will reply to it – from questions to all types of requests.
Beneath the surface, however, there’s much more going on to produce the seemingly effortless results that large language models are known for. For instance, the system first has to be created, trained, and fine-tuned to produce the type of ChatGPT results.
So, here is a quick look at the different processes that make large language models possible.
- Design: A large language model’s design will determine how it works, which algorithm and training methods to employ, as well as the time and cost for the overall training and maintenance.
- Transformers: Most large language models are built using the transformer deep learning model. Transformers are helpful because they feature a self-attention mechanism that makes them more context-aware and therefore, require less training time compared to older models.
- Pre-training & Data: From Wikipedia to large databases and other unique data sources, the quantity and quality of the data used in training a large language model will determine its output capabilities. Pre-training gives a large language model the basic information it needs to understand written text, language, context, and so on. Most LLM pre-training is done using unlabeled data in either semi-supervised or self-supervised learning modes.
- Fine-tuning: After the pre-training stage of an LLM, the next step is usually domain-specific fine-tuning to turn it into a more useful tool for specific purposes such as chatting, business research, code completion, and so on. This is the stage where tools like GitHub Copilot and OpenAI’s ChatGPT are developed.
Large Language Models & Software Tools
A large language model can also connect to other software systems or platforms through plugins and API integration. This allows the LLM to effect real-world activities, such as checking the time, performing arithmetic, browsing the web, and interacting with web apps through platforms like Zapier.
This is a currently developing area and the possibilities are massive. For instance, all you have to do is give the instructions, and the LLM can look up stuff for you on the web, make reservations, keep an eye on breaking news topics, do your shopping, and so on.
LLM Terms & Labels
There is no specific method for developing a large language model, so developer groups end up with different models that use slightly different approaches to reach similar goals. This situation has given rise to different labels, as they try to describe how each model works. Following are some of these terms and what they mean.
- Zero-shot model: A pre-trained large language model able to make classifications beyond its basic training set and to give fairly accurate results for general use.
- Fine-tuned Model: A domain-specific model.
- The Multi-modal Model: Able to understand and produce media types other than text, such as images.
- GPT: Generative Pre-trained Transformer.
- T5: Text-to-Text Transfer Transformer.
- BART: Bidirectional and Auto-Regressive Transformer.
- BERT: Bidirectional Encoder Representations from Transformers.
- RoBERTa: Robustly Optimized BERT Approach.
- CTRL: Conditional Transformer Language Model.
- LlaMA: Large Language Model Meta AI.
- Turing NLG: Natural Language Generation.
- LaMDA: Language Models for Dialogue Applications.
- ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately.
Applications of Large Language Models
Large language models can be usefully applied to many areas for business, development, and research. The real benefits come after fine-tuning, which completely depends on what the model is designed for. Here are their many areas of application.
- Language Translation: Large language models perform well with multiple languages. They can translate simple sentences into computer code or even churn out multiple human language translations at a go.
- Content Generation: From text generation to images and beyond, LLMs can be profitably employed to generate all sorts of content, including product descriptions, marketing content, company emails, and even legal documents.
- Virtual Assistants: Their good understanding of human language makes LLMs ideal virtual assistants. They can accept human language as a command and use it to write stuff, perform online actions, carry out research, and more.
- Chat & Conversations: They are also great chat partners, as the popular ChatGPT model demonstrates.
- Question Answering: Large language models absorb lots of information during training, and this makes them able to answer most general-knowledge questions.
- Content Summary: They can also summarize large text content into shorter forms. Transformer models are great at this.
- Financial Analysis: BloombergGPT is a great example of this.
- Code Generation: Computer programmers are becoming more efficient with copilots powered by large language models fine-tuned for programming.
- Transcription Services: LLMs make it easy to conduct text-to-speech and speech-to-text transcriptions on the fly.
- Rewriting Content: Either in the same language or in a different style.
- Sentiment Analysis: LLMs can be used to effectively deduce embedded sentiments in human communications. This can be profitably applied by marketing teams studying their customers.
- Information Retrieval: Their good understanding of human language makes LLMs an important part of modern search engines.
- Education: From interactive learning tools to smarter and personalized tutoring and grading systems, the potential applications of LLMs in education are vast.
The Benefits of Large Language Models
Despite the many challenges posed by large language model development, its benefits are many and worth the trouble. Here are the major ones.
- Rich Understanding of Language: LLMs can understand and respond to your language as though you were speaking to another human. This makes them especially valuable as an interface between humans and the computer world.
- Creativity: Generative pre-trained transformers have proven their capabilities in producing impressive text outputs such as by ChatGPT and images, as with Stable Diffusion.
- Versatility: A zero-shot model is a versatile tool that can be employed for many tasks and projects requiring different environments and applications.
- Fine-tuning Ability: Any organization can take a pre-trained model and fine-tune it to take up tasks and processes in their workflow. And this includes soaking in the organization’s culture and ethics like branding, slogans, and approaches.
The Challenges
Large language models present many challenges, which have made them the domain of mostly well-funded corporations. Here are the major issues developers face with LLMs.
- Development & Maintenance Costs: Large language models are both expensive to develop and maintain.
- Scale & Complexity: The name says it all. Large language models are huge and complex. You need a good team to build and manage one.
- Biases & Inaccuracies: Given the sheer size of unsupervised learning they undergo, large language models can include lots of biases and inaccuracies just as they picked them up.
List of Popular Large Language Models
| S/N | Name | Year | Developer | Corpus Size | Parameters | License |
|---|---|---|---|---|---|---|
| 1. | GPT-4 | 2023 | OpenAI | Unknown | ~ 1 trillion | Public API |
| 2. | PanGu-Σ | 2023 | Huawei | 329 billion tokens | 1 trillion | Proprietary |
| 3. | MT-NLG | 2021 | Microsoft/Nvidia | 338 billion tokens | 530 billion | Restricted |
| 4. | Open Assistant | 2023 | LAION | 1.5 trillion tokens | 17 billion | Apache 2.0 |
| 5. | BloombergGPT | 2023 | Bloomberg L.P | 700+ billion tokens | 50 billion | Proprietary |
| 6. | LLaMA | 2023 | Meta | 1.4 trillion | 65 billion | Restricted |
| 7. | Galactica | 2022 | Meta | 106 billion tokens | 120 billion | CC-BY-NC |
| 8. | Cerebras-GPT | 2023 | Cerebras | – | 13 billion | Apache 2.0 |
| 9. | BLOOM | 2022 | HugginFace & Co | 350 billion tokens | 175 billion | Responsible AI |
| 10. | GPT-Neo | 2021 | EleutherAI | 825 GB | 2.7 billion | MIT |
| 11. | Falcon | 2023 | TII | 1 trillion tokens | 40 billion | Apache 2.0 |
| 12. | GLaM | 2021 | 1.6 trillion tokens | 1.2 trillion | Proprietary | |
| 13. | GPT-3 | 2020 | OpenAI | 300 billion tokens | 175 billion | Public API |
| 14. | BERT | 2018 | 3.3 billion | 340 million | Apache | |
| 15. | AlexaTM | 2022 | Amazon | 1.3 trillion | 20 billion | Public API |
| 16. | YaLM | 2022 | Yandex | 1.7 TB | 100 billion | Apache 2.0 |
Open-source LLMs
Many of the popular large language models are open-source projects, although their complexities and huge costs make it impossible for many developers to adopt them. However, you can still run the trained models for either research purposes or production on their developer’s infrastructure. Some are free, while others are affordable. Here is a nice list.
List of Top LLM Resources
The following is a list of the web’s top resources for learning everything about and keeping up with large language models and the AI industry.
- OpenAI: Developers of ChatGPT, GPT-4, and Dall-E
- Huggin Face: Popular website for AI-related stuff from natural language processing (NLP) to large language models
- Google AI Blog: Offers information, research updates, studies, and articles from Google’s research team.
- GitHub: Popular code hosting platform with lots of open-source projects and their codes.
- Nvidia: Makers of parallel computing hardware
- ACL Anthology: Large platform with 80k+ papers on natural language processing and computational linguistics.
- Neurips: Neural information processing systems conference.
- Medium: Blogging platform with lots of AI and machine learning blogs from various experts and researchers.
- ArXiv: Major scientific repository with all types of research papers, including AI and large language models.
Frequently Asked Questions
Following are some frequently asked questions about large language models.
What is a parameter in large language models?
A parameter is any variable that can be adjusted during a model’s training to help turn input data into the right output. The more parameters an AI has, the more versatile and powerful it can be. In other words, an AI model’s capabilities are determined by its number of parameters.
What does corpus mean?
Corpus simply refers to all the data used in training an AI model.
What does training & pre-training mean?
AI training in machine learning refers to the process of providing an AI model with structured data and teaching it what they mean either using supervised or unsupervised learning – this is, with or without a human supervisor. Pre-training, on the other hand, refers to a large language model that has already been trained and is ready for fine-tuning or specific training.
What is the attention mechanism in an LLM?
Attention is used to understand the context of any information, such as when a model encounters a word that can have multiple meanings. It can deduce the exact meaning by focusing on context.
What is the difference between parameters and tokens in LLM?
Parameters are numerical values that are used to define the model’s behavior by adjusting them during training. Tokens, on the other hand, are units of meaning, such as a word, a prefix, a number, punctuation, etc.
Conclusion
Rounding up this exploration of large language models and what they are, you will agree that they are changing the world and are here to stay.
While your organization’s technical capabilities determine if you can participate here or not, your business can always leverage the many benefits of generative AI provided by large language models.

Related Articles