Вычисления на GPU — что это?
Вы постоянно слышите о вычислениях на GPU или ускорении, но не понимаете, что они означают? Вот все, что вам нужно знать.
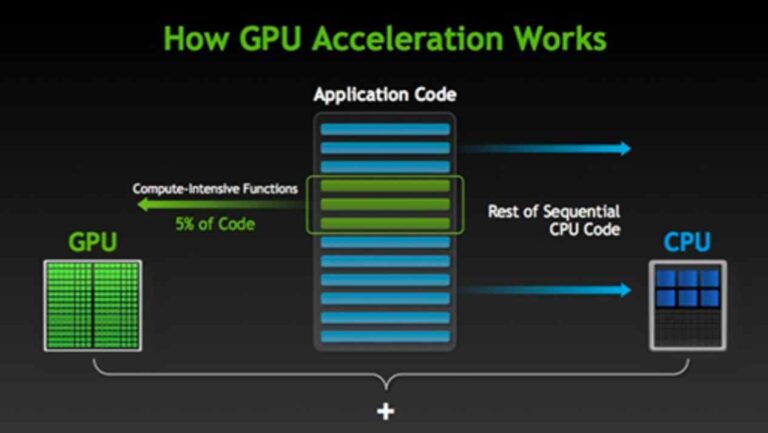
Графические процессоры или графические процессоры присутствуют во всех электронных схемах, которые создают ту или иную форму отображения, особенно в компьютере.
Ранние графические процессоры были относительно простыми. Но с появлением игр, 3D-анимации и задач рендеринга видео, которые заставили ЦП выйти за пределы своих возможностей, на помощь пришли более мощные графические процессоры.
Эти новые GPU-карты со временем становились все более мощными и сложными, поскольку разные компании и исследователи искали способы использовать свое преимущество в параллельном выполнении. Этот пост показывает вам, как это было до сих пор.
Содержание
скрывать
Что такое графический процессор?
Графический процессор или графический процессор — это специализированная схема, предназначенная для манипулирования данными, чтобы помочь в создании изображений для отображения. Другими словами, графический процессор — это система, которая создает изображения, которые вы видите на любой поверхности дисплея, такой как монитор компьютера, экран смартфона, игровая приставка и так далее.
Графические процессоры изначально были простыми устройствами, которые объединяли графические элементы для создания идеального вывода для конкретного устройства. Однако со временем и с появлением компьютерных игр сложность и мощность графических процессоров стали расти, что породило GPGPU или вычисления общего назначения на графических процессорах.
Что такое вычисления на GPU?
Вычисления на графическом процессоре или GPGPU — это использование графического процессора для вычислений помимо графики. Это означает использование графических процессоров, встроенных в видеокарту компьютера и изначально предназначенных для обработки компьютерной графики, для вычисления других типов данных, таких как научное моделирование, майнинг криптовалюты, алгебраические вычисления, прогнозирование погоды, нейронные сети и так далее.
Причина такой эволюции вычислений на GPU связана с впечатляющим развитием графических процессоров, которые происходят из распределенной параллельной архитектуры современных систем на GPU.
По мере того, как процессор компьютера становился все более мощным и мог справляться с более сложными программами и играми, производители видеокарт также старались идти в ногу с развитием современных вычислений и трехмерной графики. Nvidia представила GeForce 256 в 1999 году как первая в мире видеокарта с графическим процессором, и оттуда все пошло.
Основным преимуществом карт GPU перед ЦП является их архитектура параллельной обработки, которая позволяет им обрабатывать большие задачи данных распределенным, параллельным образом, что предотвращает узкие места и зависания ЦП.
Каковы приложения для вычислений на GPU?
Применений вычислений на GPU много, вот некоторые из них:
- Машинное обучение и нейронные сети
- Нечеткая логика
- Биоинформатика
- Молекулярное моделирование
- Видео рендеринг
- Геометрические вычисления
- Климатические исследования и прогнозирование погоды
- астрофизика
- Криптография
- Компьютерное зрение
- Взлом пароля
- Квантовые исследования
GPU против CPU обработки
Графические и центральные процессоры обрабатывают цифровые данные, но делают это по-разному. ЦП или центральный процессор предназначены для последовательной обработки на высоких скоростях, а графические процессоры предназначены для параллельной обработки на гораздо более низких скоростях. Конечно, ЦП может использовать гиперпоточность для получения 2 потоков на ядро или даже иметь десятки ядер, но в основном это последовательные процессоры.
В то время как процессоры могут иметь несколько ядер, современные графические процессоры имеют тысячи ядер, например, Nvidia GeForce RTX 3090 который имеет более 10 тысяч ядер. Однако, чтобы получить преимущество перед ЦП, данные должны быть способны к параллельной обработке, например, к обработке потока, содержащего тысячи изображений одновременно.
GPU против ASIC
ASIC расшифровывается как Application Specific Integrated Circuit, и это означает, что он может выполнять только одну задачу, то есть задачу, для выполнения которой он был разработан. ASIC — это уникальная машина, разработанная с нуля и требующая экспертных знаний об оборудовании для сборки. ASIC обычно используются в майнинге криптовалюты, поскольку они предлагают хорошие преимущества параллельной обработки и более высокую эффективность, чем графические процессоры.
Однако основное различие между ними заключается в том, что графические процессоры более универсальны. Например, вы можете легко построить установку для майнинга криптовалюты с использованием графических процессоров. Детали легко доступны, и если вы закончили майнинг, вы всегда можете продать видеокарту геймерам или другим майнерам. Однако с ASIC вы можете продать только подержанную машину другим майнерам, потому что вы вряд ли сможете с ней что-то еще сделать.
Помимо майнинга криптовалюты, становится еще труднее заполучить машины ASIC, потому что они не являются массовыми продуктами. Это сильно контрастирует с системами на GPU, которые вы можете получить везде и легко настроить.
GPU против кластерных вычислений
В то время как одна карта GPU содержит тысячи ядер, которые добавляют огромную мощность любому компьютеру, к которому вы ее подключаете, теоретически вы можете добавить столько карт GPU к материнской плате компьютера, сколько она может обслуживать, и еще больше увеличить ее вычислительную мощность.
Компьютерный кластер, с другой стороны, относится к нескольким компьютерам, которые объединены в сеть и функционируют как один большой компьютер — суперкомпьютер. Каждый компьютер в сети называется узлом и может иметь на борту многоядерный процессор, а также одну или несколько карт GPU.
В каждом кластере должен быть главный узел, являющийся передним компьютером, который отвечает за управление рабочими узлами и их планирование. Он также будет содержать программное обеспечение, которое выделяет данные и программы для своих рабочих узлов для вычисления и возврата результатов.
Ускорение графического процессора против гиперпоточности
ЦП предназначен для одновременной обработки нескольких задач, и поэтому он работает на очень высоких скоростях, планируя время обработки между этими несколькими процессами. Однако, когда он сталкивается с функцией, интенсивно использующей вычисления, он может провести некоторое время в цикле, прежде чем вернуться к другим процессам. Обычно это приводит к общему замедлению работы компьютера, а в худших случаях и к полному зависанию системы.
Разработчики компьютеров могут избежать этого ужасного сценария, используя гиперпоточность или ускорение графического процессора. Гиперпоточность позволяет одному ядру ЦП функционировать как два потока обработки. Таким образом, когда один поток застревает в цикле с интенсивными вычислениями, другой поток все еще может удерживать систему вместе.
Современные компьютеры теперь имеют несколько ядер от 2 до 4, 8, 16, 32 и так далее. Кроме того, они поддерживают гиперпоточность, поэтому 2-ядерный ЦП предлагает 4 потока, 4-ядерный — 8 потоков и так далее.
Гиперпоточность с многоядерными ЦП решит большинство вычислительных проблем, предотвратит узкие места и обеспечит максимальную производительность в простых играх, создании музыки и небольших проектах по графике, видео и машинному обучению. Но когда вам нужно больше мощности, то GPU часто является правильным решением.
GPU или аппаратное ускорение — это способность программного приложения использовать мощность параллельной обработки графических процессоров для обработки больших объемов данных без перегрузки ЦП. Многие профессиональные приложения зависят от ускорения графического процессора. К ним относятся программы для дизайна/рендеринга видео и анимации, кодировщики, криптография, большие нейронные сети и так далее.
Основы программирования GPGPU
Программирование общего назначения графических процессоров первоначально выполнялось с использованием DirectX и OpenGL библиотеки. Однако они были разработаны исключительно для разработки графики, поэтому вам приходилось переназначать свои данные в графические модели, чтобы они работали.
К счастью, за прошедшие годы в GPGPU произошли значительные улучшения, что привело к появлению библиотек, языков программирования и фреймворков. Наиболее популярным из этих фреймворков является CUDA от Nvidia.
CUDA позволяет любому разработчику легко погрузиться в программирование GPU, не зная основ классического программирования GPU. Он предоставляет функции, которые расширяют возможности разработки помимо графики, а многие модули даже имеют функции, специфичные для машинного обучения.
Доступные библиотеки также упрощают создание новых программ с ускорением на GPU с нуля или адаптацию предварительно написанных программ к параллельной обработке. Вы выбираете правильную библиотеку, оптимизируете свой код для параллельных циклов, перекомпилируете и все.
Ядра CUDA против потоковых процессоров
Часто вы сталкиваетесь с терминами Ядра Cuda и потоковые процессоры. Оба термина просто относятся к ядру графического процессора или Арифметико-логические устройства графического процессора. CUDA Core — это проприетарная технология Nvidia, а процессоры Stream — AMD.
Другой термин, с которым вы можете столкнуться, — это Streaming Multi-Processor или SM. Это еще одна технология Nvidia, изначально сгруппировавшая 8 ядер CUDA на SM. Он выполняет 32-поточные деформации за раз, используя 4 такта на команду. Новые разработки теперь имеют более 100 ядер на потоковый мультипроцессор.
Лучшие языки и библиотеки графических процессоров
Существует так много библиотек и языков, которые работают как на платформах Nvidia CUDA, так и на платформах AMD. Вот лишь некоторые из них:
- Nvidia CUBLAS – Базовые подпрограммы линейной алгебры для CUDA
- cuDNN – Библиотека глубоких нейронных сетей
- OpenCL – Открытый стандарт для параллельного программирования
- Openmp – Для графических процессоров AMD
- HIP - библиотека С++
- Nvidia КУРАНД – Генерация случайных чисел
- cuFFT – Для быстрого преобразования Фурье
- Nvidia АЭС – 2D изображения и обработка сигналов
- ГП ВСИПЛ – векторное изображение и обработка сигналов
- OpenCV — Библиотека графического процессора для компьютерного зрения
- OpenACC – Язык для параллельной разработки
- ПиКУДА – Python для платформы CUDA
- ТензорРТ – Глубокое обучение для CUDA
- CUDA C ++ – язык C++ для CUDA
- CUDA С - Язык C для CUDA
- CUDA Фортран – CUDA для разработчиков FORTRAN
Лучшие кластерные проекты GPU
По состоянию на июнь 2022 года 8 из 10 самых быстрых суперкомпьютеров в мире имеют ускорение на GPU. Все они также используют ОС Linux и выглядят следующим образом:
| Ранг | Имя | петафлопс | Процессорные ядра | Ядра GPU | Мощность (кВт) | Год |
| 1. | Граница | 1,102 | 591,872 | 8,138,240 | 21,100 | 2022 |
| 2. | LUMI | 151.90 | 75,264 | 1,034,880 | 2,900 | 2022 |
| 3. | Саммит | 148.6 | 202,752 | 2,211,840 | 10,096 | 2018 |
| 4. | Sierra | 94.64 | 190,080 | 1,382,400 | 7,438 | 2018 |
| 5. | Перлмуттер | 64.59 | ARCXNUMX | ARCXNUMX | 2,589 | 2021 |
| 6. | Селена | 63.46 | 71,680 | 483,840 | 2,646 | 2020 |
| 7. | Tianhe-2 | 61.445 | 427,008 | 4,554,752 | 18,482 | 2013 |
| 8. | Адастра | 46.1 | 21,632 | 297,440 | 921 | 2022 |
Заключение
Дойдя до конца этого погружения в вычисления на GPU и все, что с ними связано, вы уже должны были получить представление о его мощности и возможностях.
Для получения дополнительной информации вы можете проверить платформу разработчика Нвидиа здесь или что из AMD здесь.

Статьи по теме