GPU-computing - wat is het?
Hoor je steeds over GPU-computing of -versnelling, maar weet je niet zeker wat ze betekenen? Hier is alles wat u moet weten.
GPU of grafische verwerkingseenheden zijn aanwezig in alle elektronische circuits die de ene of de andere vorm van weergave produceren, met name de computer.
Vroege grafische processors waren relatief eenvoudig. Maar met de komst van gaming, 3D-animatie en video-renderingtaken die CPU's buiten hun limieten duwden, moesten krachtigere GPU's te hulp komen.
Deze nieuwe GPU-kaarten groeiden in de loop van de tijd in kracht en complexiteit, waarbij verschillende bedrijven en onderzoekers manieren zochten om hun parallelle uitvoeringsvoordeel te benutten. Dit bericht laat zien hoe het tot nu toe gaat.
Inhoudsopgave
verstoppen
Wat is een GPU?
Een GPU of Graphics Processing Unit is een gespecialiseerd circuit dat is ontworpen voor de manipulatie van gegevens om te helpen bij het maken van afbeeldingen voor weergave. Met andere woorden, een GPU is een systeem dat de afbeeldingen maakt die u op elk weergaveoppervlak ziet, zoals de computermonitor, het smartphonescherm, gameconsoles, enzovoort.
GPU's waren aanvankelijk eenvoudige apparaten die grafische elementen samenvoegden om een ideale uitvoer voor een specifiek apparaat te creëren. In de loop van de tijd, en met de komst van computergaming, begonnen GPU's echter in complexiteit en kracht te groeien, wat leidde tot GPGPU of General Purpose Computing op GPU's.
Wat is GPU-computing?
GPU-computing of GPGPU is het gebruik van een GPU voor berekeningen die verder gaan dan grafische afbeeldingen. Dit betekent het gebruik van de GPU's die zijn ingebed in de videokaart van een computer en oorspronkelijk bedoeld waren voor het verwerken van computergraphics voor de berekening van andere soorten gegevens, zoals wetenschappelijke simulaties, cryptocurrency-mining, algebra-berekeningen, weersvoorspellingen, neurale netwerken, enzovoort.
De reden voor deze evolutie van GPU-computing komt van de indrukwekkende ontwikkeling van grafische verwerkingseenheden, die voortkomt uit de gedistribueerde parallelle architectuur van moderne GPU-systemen.
Naarmate de CPU van de computer krachtiger werd en complexere programma's en games aankon, probeerden videokaartmakers ook gelijke tred te houden met de ontwikkelingen op het gebied van moderne computers en 3D-graphics. Nvidia onthulde de GeForce 256 in 1999 als 's werelds eerste GPU-videokaart en de dingen zijn van daaruit geëvolueerd.
Het grote voordeel van GPU-kaarten ten opzichte van CPU's is hun parallelle verwerkingsarchitectuur, waardoor ze grote gegevenstaken op een gedistribueerde, parallelle manier kunnen verwerken, waardoor knelpunten en CPU-bevriezingen worden voorkomen.
Wat zijn de toepassingen voor GPU-computing?
De toepassingen van GPU-computing zijn talrijk, hier is een blik op enkele topgebruiken:
- Machine learning en neurale netwerken
- Fuzzy logic
- Bio-informatica
- Moleculaire modellering
- Videoweergave
- Geometrisch rekenen
- Klimaatonderzoek en weersvoorspelling
- astrofysica
- Geheimschrift
- Computer visie
- Wachtwoord kraken
- Kwantumonderzoek
GPU versus CPU-verwerking
GPU's en CPU's verwerken beide digitale gegevens, maar ze doen dit op verschillende manieren. De CPU of centrale verwerkingseenheid is ontworpen voor seriële verwerking met hoge snelheden, terwijl GPU's zijn ontworpen voor parallelle verwerking met veel lagere snelheden. Natuurlijk kan een CPU hyperthreading gebruiken om 2 threads per core te krijgen, of zelfs tientallen cores, maar het zijn in wezen seriële processors.
Hoewel CPU's een paar kernen kunnen hebben, worden moderne GPU's geleverd met duizenden kernen, bijvoorbeeld de Nvidia GeForce RTX 3090 met 10K+ cores. Om echter een voordeel ten opzichte van CPU's te krijgen, moeten de gegevens parallel kunnen worden verwerkt, zoals het verwerken van een stream met duizenden afbeeldingen tegelijk.
GPU's versus ASIC's
ASIC staat voor Application Specific Integrated Circuit en dit betekent dat het maar één taak kan uitvoeren, namelijk de taak waarvoor het is ontworpen. Een ASIC is een unieke machine die helemaal opnieuw is ontwikkeld en waarvoor deskundige hardwarekennis nodig is om te bouwen. ASIC's worden vaak gebruikt in cryptocurrency-mining, omdat ze goede parallelle verwerkingsvoordelen en een betere efficiëntie bieden dan GPU's.
Het grote verschil tussen de twee is echter dat GPU's veelzijdiger zijn. U kunt bijvoorbeeld eenvoudig een cryptocurrency-mijnbouwinstallatie bouwen met behulp van GPU's. De onderdelen zijn gemakkelijk verkrijgbaar en als je klaar bent met minen, kun je de GPU-kaart altijd verkopen aan gamers of andere miners. Met ASIC's kun je een gebruikte machine echter alleen aan andere miners verkopen, omdat je er bijna niets anders mee kunt doen.
Afgezien van cryptocurrency-mining, wordt het nog moeilijker om een ASIC-machine in handen te krijgen, omdat het geen massaproducten zijn. Dit staat in schril contrast met GPU-systemen die je overal kunt krijgen en eenvoudig kunt configureren.
GPU versus clustercomputing
Hoewel een enkele GPU-kaart duizenden kernen bevat, die enorme kracht toevoegen aan elke computer waarop u deze aansluit, kunt u in theorie zoveel GPU-kaarten aan het moederbord van de computer toevoegen als het aankan, en de verwerkingscapaciteit verder vergroten.
Een computercluster daarentegen verwijst naar meerdere computers die in een netwerk met elkaar zijn verbonden om te functioneren als één grote computer - een supercomputer. Elke computer op het netwerk wordt een knooppunt genoemd en kan een multi-core CPU hebben, evenals een of meer GPU-kaarten aan boord.
Elk cluster moet een hoofdknooppunt hebben. Dit is de frontcomputer die verantwoordelijk is voor het beheren en plannen van de werkknooppunten. Het zal ook software bevatten die gegevens en programma's toewijst aan de werkknooppunten om resultaten te berekenen en te retourneren.
GPU-versnelling versus hyperthreading
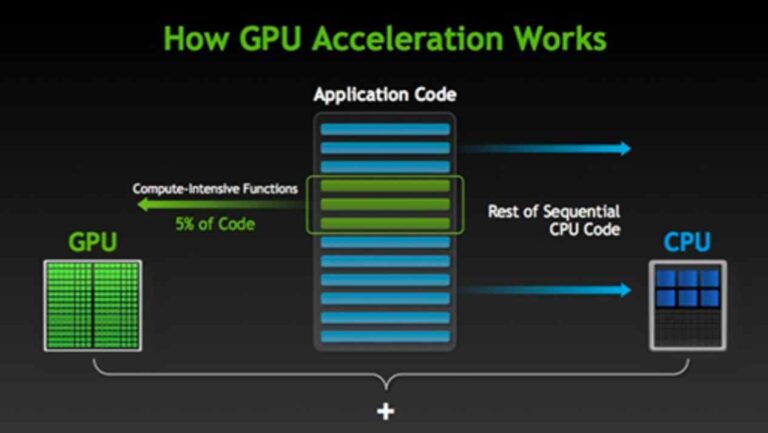
De CPU is ontworpen om meerdere taken tegelijk af te handelen, en daarom werkt hij op zeer hoge snelheden, waarbij de verwerkingstijd tussen die meerdere processen wordt ingepland. Wanneer het echter een rekenintensieve functie tegenkomt, kan het een tijdje in de lus blijven voordat het terugkeert naar de andere processen. Dit resulteert meestal in een algemene vertraging van de computer en, in het ergste geval, een volledige bevriezing van het systeem.
Computerontwerpers kunnen dit gevreesde scenario vermijden door hyperthreading of GPU-versnelling te gebruiken. Hyper-threading zorgt ervoor dat een enkele CPU-kern kan functioneren als twee verwerkingsthreads. Dus als de ene thread vastzit in een rekenintensieve lus, kan de andere thread het systeem nog steeds bij elkaar houden.
Moderne computers hebben nu meerdere kernen van 2 tot 4, 8, 16, 32, enzovoort. Bovendien beschikken ze over hyper-threading, dus een 2-core CPU biedt 4 threads, een 4-core biedt 8 threads, enzovoort.
Hyperthreading met multi-core CPU's lost de meeste computerproblemen op, voorkomt knelpunten en levert topprestaties met eenvoudige games, muziekproductie en kleine grafische, video- en machine learning-projecten. Maar heb je meer kracht nodig dan dat, dan is een GPU vaak de juiste oplossing.
GPU of hardwareversnelling is het vermogen van een softwaretoepassing om de parallelle verwerkingskracht van een GPU te benutten om grote hoeveelheden gegevens te verwerken, zonder dat de CPU vastloopt. Veel professionele applicaties zijn afhankelijk van GPU-versnelling om goed te kunnen functioneren. Deze omvatten video- en animatieontwerp-/renderingprogramma's, encoders, cryptografie, grote neurale netwerken, enzovoort.
Basisprincipes van GPGPU-programmering
Het programmeren van GPU's voor algemene doeleinden werd aanvankelijk gedaan met behulp van DirectX en OpenGL bibliotheken. Deze zijn echter uitsluitend ontworpen voor grafische ontwikkeling, dus u moest uw gegevens opnieuw gebruiken in grafisch-achtige modellen om te werken.
Gelukkig zijn er in de loop der jaren grote vorderingen gemaakt in GPGPU, wat heeft geleid tot bibliotheken, programmeertalen en frameworks. De meest populaire van deze frameworks is CUDA van Nvidia.
CUDA maakt het voor elke ontwikkelaar gemakkelijk om in GPU-programmering te duiken zonder de kern van klassieke GPU-programmering te hoeven kennen. Het biedt functies die de ontwikkeling buiten de grafische weergave verbeteren, met veel eenheden zelfs met machine-learning-specifieke functies.
Beschikbare bibliotheken maken het ook gemakkelijk om vanaf het begin nieuwe GPU-versnelde programma's te maken of om vooraf geschreven programma's aan te passen aan parallelle verwerking. U kiest de juiste bibliotheek, optimaliseert uw code voor parallelle lussen, hercompileert en dat is alles.
CUDA-kernen versus streamprocessors
Vaak kom je de termen tegen Cuda-kernen en stream-processors. Beide termen verwijzen eenvoudigweg naar de GPU-kern of Rekenkundige logische eenheden van een GPU. CUDA Core is een gepatenteerde technologie van Nvidia, terwijl Stream-processors van AMD zijn.
Een andere term die je misschien tegenkomt is Streaming Multi-Processor of SM. Dit is een andere Nvidia-technologie die oorspronkelijk 8 CUDA-kernen per SM groepeerde. Het voert 32-draads warps in één keer uit, met behulp van 4 klokcycli per commando. Nieuwere ontwerpen hebben nu meer dan 100 cores per streaming multi-processor.
Top GPU-talen en bibliotheken
Er zijn zoveel bibliotheken en talen die werken op zowel Nvidia CUDA- als AMD-platforms. Hieronder volgen er slechts een paar:
- Nvidia cuBLAS – Basis lineaire algebra subprogramma's voor CUDA
- cuDNN – Diepe bibliotheek met neurale netwerken
- OpenCL – Open standaard voor parallel programmeren
- Openmp – Voor AMD GPU's
- HEUP – C++ bibliotheek
- Nvidia cuRAND - Willekeurige nummergeneratie
- manchet – Voor Fast Fourier-transformatie
- Nvidia-kerncentrale – 2D beeld- en signaalverwerking
- GPU-VSIPL – Vectorbeeld- en signaalverwerking
- OpenCV - GPU-bibliotheek voor computervisie
- OpenACC – Taal voor parallelle ontwikkeling
- PyCUDA – Python voor CUDA-platform
- TensorRT – Diep leren voor CUDA
- CUDA C++ – C++-taal voor CUDA
- CUDA C – C-taal voor CUDA
- CUDA Fortran – CUDA voor FORTRAN-ontwikkelaars
Top GPU-clusterprojecten
Vanaf juni 2022 zijn 8 van de 10 snelste supercomputers ter wereld GPU-versneld. Ze delen allemaal ook het Linux-besturingssysteem en zijn als volgt:
| Rang | Naam | Petaflops | CPU-cores | GPU-kernen | Vermogen (kW) | Jaar |
| 1. | Grens | 1,102 | 591,872 | 8,138,240 | 21,100 | 2022 |
| 2. | LUMI | 151.90 | 75,264 | 1,034,880 | 2,900 | 2022 |
| 3. | Top | 148.6 | 202,752 | 2,211,840 | 10,096 | 2018 |
| 4. | Sierra | 94.64 | 190,080 | 1,382,400 | 7,438 | 2018 |
| 5. | Perlmutter | 64.59 | NB | NB | 2,589 | 2021 |
| 6. | Selene | 63.46 | 71,680 | 483,840 | 2,646 | 2020 |
| 7. | Tianhe-2 | 61.445 | 427,008 | 4,554,752 | 18,482 | 2013 |
| 8. | adastra | 46.1 | 21,632 | 297,440 | 921 | 2022 |
Conclusie
Aan het einde van deze duik in GPU-computing en alles wat daarbij komt kijken, zou je nu een idee moeten hebben gekregen van de kracht en reikwijdte ervan.
Voor meer informatie kunt u het ontwikkelaarsplatform van . bekijken Nvidia hier of die van AMD hier.

Gerelateerde artikelen