Computação GPU – O que é?
Você continua ouvindo sobre computação ou aceleração de GPU, mas não tem certeza do que eles significam? Aqui está tudo o que você precisa saber.
GPU ou Unidades de Processamento Gráfico estão presentes em todos os circuitos eletrônicos que produzem uma forma de exibição ou outra, principalmente o computador.
Os primeiros processadores gráficos eram relativamente simples. Mas com o advento dos jogos, animação 3D e tarefas de renderização de vídeo que levaram as CPUs além de seus limites, GPUs mais poderosas tiveram que vir em socorro.
Essas novas placas de GPU cresceram em poder e complexidade ao longo do tempo, com diferentes empresas e pesquisadores buscando maneiras de alavancar sua vantagem de execução paralela. Este post mostra como está indo até agora.
Conteúdo
esconder
O que é uma GPU?
Uma GPU ou Unidade de Processamento Gráfico é um circuito especializado projetado para a manipulação de dados para auxiliar na criação de imagens para exibição. Em outras palavras, uma GPU é um sistema que cria as imagens que você vê em qualquer superfície de exibição, como monitor de computador, tela de smartphone, consoles de jogos e assim por diante.
As GPUs eram inicialmente dispositivos simples que uniam elementos gráficos para criar uma saída ideal para um dispositivo específico. Com o tempo, no entanto, e com o advento dos jogos de computador, as GPUs começaram a crescer em complexidade e poder, dando origem a GPGPU ou computação de uso geral em GPUs.
O que é computação GPU?
A computação GPU ou GPGPU é o uso de uma GPU para computação além dos gráficos. Isso significa usar as GPUs incorporadas na placa de vídeo de um computador e originalmente destinadas ao processamento de gráficos de computador para o cálculo de outros tipos de dados, como simulações científicas, mineração de criptomoedas, cálculos de álgebra, previsão do tempo, redes neurais e assim por diante.
A razão para esta evolução da computação GPU vem do impressionante desenvolvimento de unidades de processamento gráfico, que vem da arquitetura paralela distribuída dos modernos sistemas GPU.
À medida que a CPU do computador se tornava mais poderosa e podia lidar com programas e jogos mais complexos, os fabricantes de placas de vídeo também tentavam acompanhar os desenvolvimentos da computação moderna e dos gráficos 3D. A Nvidia revelou o GeForce 256 em 1999 como a primeira placa de vídeo GPU do mundo e as coisas evoluíram a partir daí.
A principal vantagem das placas de GPU sobre as CPUs é sua arquitetura de processamento paralelo, que as torna capazes de processar grandes tarefas de dados de maneira distribuída e paralela, evitando gargalos e congelamentos de CPU.
Quais são os aplicativos para computação GPU?
As aplicações da computação GPU são muitas, veja alguns dos principais usos:
- Aprendizado de máquina e redes neurais
- Lógica difusa
- Bioinformática
- Modelagem molecular
- Renderização de vídeo
- Computação geométrica
- Pesquisa Climática e previsão do tempo
- Astrofísica
- Criptografia
- Visão computacional
- Quebra de senha
- Pesquisa quântica
Processamento de GPU vs CPU
GPUs e CPUs processam dados digitais, mas o fazem de maneiras diferentes. A CPU ou unidade central de processamento é projetada para processamento serial em altas velocidades, enquanto as GPUs são projetadas para processamento paralelo em velocidades muito mais baixas. Claro, uma CPU pode usar hyper-threading para obter 2 threads por núcleo, ou até mesmo ter dezenas de núcleos, mas são fundamentalmente processadores seriais.
Enquanto as CPUs podem ter alguns núcleos, as GPUs modernas vêm com milhares de núcleos, por exemplo, o Nvidia GeForce RTX 3090 que possui mais de 10 mil núcleos. No entanto, para obter uma vantagem sobre as CPUs, os dados precisam ser capazes de processamento paralelo, como processar um fluxo contendo milhares de imagens de uma só vez.
GPUs vs ASICs
ASIC significa Circuito Integrado Específico de Aplicação e isso significa que ele só pode executar uma tarefa - ou seja, a tarefa para a qual foi projetado. Um ASIC é uma máquina única que é desenvolvida do zero e requer conhecimento de hardware especializado para ser construída. Os ASICs são comumente usados na mineração de criptomoedas, pois oferecem bons benefícios de processamento paralelo e melhor eficiência do que as GPUs.
A principal diferença entre os dois, no entanto, é que as GPUs são mais versáteis. Por exemplo, você pode construir facilmente um equipamento de mineração de criptomoeda usando GPUs. As peças estão facilmente disponíveis e, se você terminar de minerar, sempre poderá vender a placa GPU para jogadores ou outros mineradores. Com ASICs, no entanto, você só pode vender uma máquina usada para outros mineradores, porque dificilmente pode fazer outra coisa com ela.
Além da mineração de criptomoedas, fica ainda mais difícil colocar as mãos em uma máquina ASIC, porque não são produtos de massa. Isso contrasta fortemente com os sistemas de GPU que você pode obter em qualquer lugar e configurar facilmente.
GPU vs computação em cluster
Embora uma única placa de GPU contenha milhares de núcleos, que adicionam uma tremenda potência a qualquer computador ao qual você a conecte, teoricamente você pode adicionar quantas placas de GPU à placa-mãe do computador ela puder suportar e aumentar ainda mais sua capacidade de processamento.
Um cluster de computadores, por outro lado, refere-se a vários computadores conectados em rede para funcionar como um grande computador – um supercomputador. Cada computador na rede é chamado de nó e pode ter uma CPU multi-core, bem como uma ou mais placas de GPU integradas.
Cada cluster deve ter um nó mestre, que é o computador frontal responsável por gerenciar e agendar seus nós de trabalho. Ele também conterá software que aloca dados e programas para seus nós de trabalho para calcular e retornar resultados.
Aceleração de GPU vs Hyper-threading
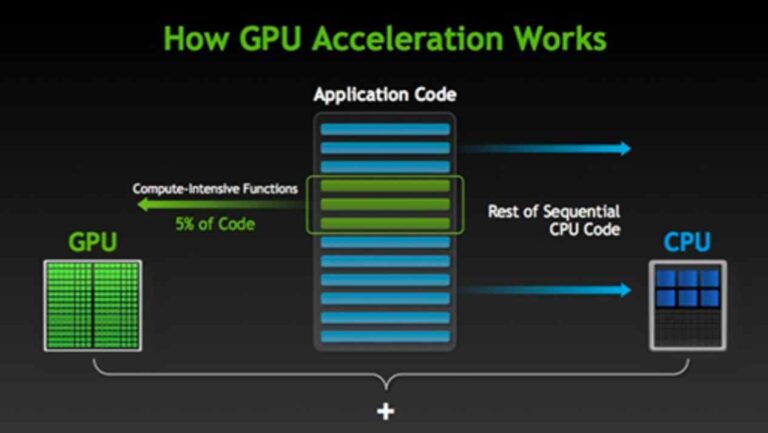
A CPU foi projetada para lidar com várias tarefas ao mesmo tempo, e é por isso que funciona em velocidades muito altas, programando o tempo de processamento entre esses vários processos. No entanto, quando encontra uma função de computação intensiva, pode passar um tempo no loop antes de retornar aos outros processos. Isso geralmente resulta em uma desaceleração geral do computador e, em casos piores, um congelamento completo do sistema.
Os designers de computador podem evitar esse cenário temido usando hyper-threading ou aceleração de GPU. Hyper-threading permite que um único núcleo de CPU funcione como dois threads de processamento. Assim, quando um encadeamento está preso em um loop de computação intensiva, o outro encadeamento ainda pode manter o sistema unido.
Os computadores modernos agora têm vários núcleos de 2 a 4, 8, 16, 32 e assim por diante. Além disso, eles apresentam hyper-threading, portanto, uma CPU de 2 núcleos oferece 4 threads, uma de 4 núcleos oferece 8 threads e assim por diante.
Hyper-threading com CPUs de vários núcleos resolverá a maioria dos problemas de computação, evitará gargalos e fornecerá o melhor desempenho com jogos simples, produção musical e pequenos projetos de gráficos, vídeos e aprendizado de máquina. Mas quando você precisa de mais energia do que isso, uma GPU geralmente é a solução certa.
A aceleração de GPU ou hardware é a capacidade de um aplicativo de software de aproveitar o poder de processamento paralelo de uma GPU para processar um grande número de dados, sem sobrecarregar a CPU. Muitos aplicativos profissionais dependem da aceleração da GPU para funcionar bem. Isso inclui programas de design/renderização de vídeo e animação, codificadores, criptografia, grandes redes neurais e assim por diante.
Noções básicas de programação GPGPU
A programação de propósito geral de GPUs foi inicialmente feita usando DirectX e OpenGL bibliotecas. No entanto, eles foram projetados estritamente para desenvolvimento de gráficos, então você teve que redefinir seus dados em modelos semelhantes a gráficos para funcionar.
Felizmente, houve grandes avanços no GPGPU ao longo dos anos, levando a bibliotecas, linguagens de programação e estruturas. O mais popular desses frameworks é o CUDA da Nvidia.
O CUDA facilita para qualquer desenvolvedor mergulhar na programação de GPU sem precisar conhecer os detalhes da programação de GPU clássica. Ele fornece recursos que aprimoram o desenvolvimento além dos gráficos, com muitas unidades apresentando até mesmo funções específicas de aprendizado de máquina.
As bibliotecas disponíveis também facilitam a criação de novos programas acelerados por GPU do zero ou a adaptação de programas pré-escritos para processamento paralelo. Você escolhe a biblioteca certa, otimiza seu código para loops paralelos, recompila e pronto.
Processadores CUDA Cores vs Stream
Muitas vezes, você encontrará os termos Núcleos Cuda e processadores de fluxo. Ambos os termos referem-se simplesmente ao núcleo da GPU ou Unidades Lógicas Aritméticas de uma GPU. CUDA Core é uma tecnologia proprietária da Nvidia, enquanto os processadores Stream são da AMD.
Outro termo que você pode encontrar é Streaming Multi-Processor ou SM. Esta é outra tecnologia da Nvidia que originalmente agrupava 8 núcleos CUDA por SM. Ele executa warps de 32 threads de uma só vez, usando 4 ciclos de clock por comando. Os designs mais recentes agora apresentam mais de 100 núcleos por multiprocessador de streaming.
Principais linguagens e bibliotecas de GPU
Existem muitas bibliotecas e linguagens por aí que funcionam nas plataformas Nvidia CUDA e AMD. Seguem apenas alguns:
- Nvidia cuBLAS – Subprogramas básicos de álgebra linear para CUDA
- cuDNN – Biblioteca de redes neurais profundas
- OpenCL – Padrão aberto para programação paralela
- Openmp – Para GPUs AMD
- QUADRIL – Biblioteca C++
- Nvidia curAND – Geração de números aleatórios
- punhoFFT – Para Transformada Rápida de Fourier
- Central nuclear da Nvidia – Processamento de imagem e sinal 2D
- GPU VSIPL – Imagem vetorial e processamento de sinal
- OpenCV – Biblioteca de GPU para visão computacional
- OpenACC – Linguagem para desenvolvimento paralelo
- PyCUDAGenericName – Python para plataforma CUDA
- TensorRT – Aprendizado profundo para CUDA
- CUDAC++ – Linguagem C++ para CUDA
- CUDA-C – Linguagem C para CUDA
- CUDA FortranGenericName – CUDA para desenvolvedores FORTRAN
Principais projetos de cluster de GPU
Em junho de 2022, 8 dos 10 supercomputadores mais rápidos do mundo são acelerados por GPU. Todos eles também compartilham o sistema operacional Linux e são os seguintes:
| Rank | Nome | Petaflops | Núcleos de CPU | Cúmulos GPU | Potência (kW) | Ano |
| 1. | Frontier | 1,102 | 591,872 | 8,138,240 | 21,100 | 2022 |
| 2. | a LUMI. | 151.90 | 75,264 | 1,034,880 | 2,900 | 2022 |
| 3. | Summit | 148.6 | 202,752 | 2,211,840 | 10,096 | 2018 |
| 4. | serra | 94.64 | 190,080 | 1,382,400 | 7,438 | 2018 |
| 5. | Perlmutter | 64.59 | N/D | N/D | 2,589 | 2021 |
| 6. | Selene | 63.46 | 71,680 | 483,840 | 2,646 | 2020 |
| 7. | Tianhe-2 | 61.445 | 427,008 | 4,554,752 | 18,482 | 2013 |
| 8. | Adstra | 46.1 | 21,632 | 297,440 | 921 | 2022 |
Conclusão
Chegando ao final deste mergulho na computação GPU e tudo o que vem com ela, você já deve ter tido uma ideia de seu poder e escopo.
Para mais informações, você pode conferir a plataforma do desenvolvedor de Nvidia aqui ou o de AMD aqui.

Artigos Relacionados