GPU-Computing – was ist das?
Hören Sie immer wieder von GPU-Computing oder -Beschleunigung, sind sich aber nicht sicher, was sie bedeuten? Hier ist alles, was Sie wissen müssen.
GPU oder Graphics Processing Units sind in allen elektronischen Schaltungen vorhanden, die die eine oder andere Form der Anzeige erzeugen, insbesondere im Computer.
Frühe Grafikprozessoren waren relativ einfach. Aber mit dem Aufkommen von Gaming-, 3D-Animations- und Video-Rendering-Aufgaben, die CPUs an ihre Grenzen brachten, mussten leistungsstärkere GPUs zur Rettung kommen.
Diese neuen GPU-Karten wuchsen im Laufe der Zeit an Leistung und Komplexität, wobei verschiedene Unternehmen und Forscher nach Wegen suchten, ihren Vorteil der parallelen Ausführung zu nutzen. Dieser Beitrag zeigt Ihnen, wie es bisher gelaufen ist.
Inhaltsverzeichnis
verstecken
Was ist eine GPU?
Eine GPU oder Grafikverarbeitungseinheit ist eine spezielle Schaltung, die für die Manipulation von Daten entwickelt wurde, um die Erstellung von Bildern für die Anzeige zu unterstützen. Mit anderen Worten, eine GPU ist ein System, das die Bilder erstellt, die Sie auf einer beliebigen Anzeigeoberfläche wie dem Computermonitor, Smartphone-Bildschirm, Spielkonsolen usw. sehen.
GPUs waren ursprünglich einfache Geräte, die grafische Elemente zusammenfügen, um eine ideale Ausgabe für ein bestimmtes Gerät zu erstellen. Im Laufe der Zeit und mit dem Aufkommen von Computerspielen begannen GPUs jedoch an Komplexität und Leistung zuzunehmen, was zu Geburten führte GPGPU oder General Purpose Computing auf GPUs.
Was ist GPU-Computing?
GPU-Computing oder GPGPU ist die Verwendung einer GPU für Berechnungen jenseits von Grafiken. Dies bedeutet die Verwendung der GPUs, die in die Grafikkarte eines Computers eingebettet sind und ursprünglich für die Verarbeitung von Computergrafiken für die Berechnung anderer Arten von Daten gedacht waren, wie z.
Der Grund für diese Entwicklung des GPU-Computing liegt in der beeindruckenden Entwicklung von Grafikprozessoreinheiten, die aus der verteilten parallelen Architektur moderner GPU-Systeme stammt.
Als die CPU des Computers leistungsfähiger wurde und komplexere Programme und Spiele handhaben konnte, versuchten die Hersteller von Grafikkarten auch, mit den Entwicklungen in der modernen Computer- und 3D-Grafik Schritt zu halten. Nvidia enthüllte die GeForce 256 im Jahr 1999 als die weltweit erste GPU-Grafikkarte und die Dinge entwickelten sich von da an.
Der Hauptvorteil von GPU-Karten gegenüber CPUs ist ihre parallele Verarbeitungsarchitektur, die es ihnen ermöglicht, große Datenaufgaben auf verteilte, parallele Weise zu verarbeiten, wodurch Engpässe und CPU-Einfrieren verhindert werden.
Was sind die Anwendungen für GPU-Computing?
Die Anwendungen von GPU-Computing sind vielfältig, hier ist ein Blick auf einige Top-Anwendungen:
- Maschinelles Lernen und neuronale Netze
- Fuzzy-Logik
- Bioinformatik
- Molekulare Modellierung
- Videowiedergabe
- Geometrisches Rechnen
- Klimaforschung und Wettervorhersage
- Astrophysik
- Cryptography
- Computer Vision
- Passwort knacken
- Quantenforschung
GPU vs. CPU-Verarbeitung
GPUs und CPUs verarbeiten beide digitale Daten, aber auf unterschiedliche Weise. Die CPU oder Zentraleinheit ist für die serielle Verarbeitung mit hohen Geschwindigkeiten ausgelegt, während GPUs für die parallele Verarbeitung mit viel niedrigeren Geschwindigkeiten ausgelegt sind. Natürlich kann eine CPU Hyper-Threading verwenden, um 2 Threads pro Kern zu erhalten, oder sogar Dutzende von Kernen haben, aber sie sind im Grunde serielle Prozessoren.
Während CPUs ein paar Kerne haben können, kommen moderne GPUs mit Tausenden von Kernen, zum Beispiel dem Nvidia GeForce RTX 3090 mit mehr als 10 Kernen. Um einen Vorteil gegenüber CPUs zu erzielen, müssen die Daten jedoch parallel verarbeitet werden können, z. B. die Verarbeitung eines Streams mit Tausenden von Bildern auf einmal.
GPUs vs. ASICs
ASIC steht für Application Specific Integrated Circuit und das bedeutet, dass er nur eine Aufgabe erfüllen kann – nämlich die Aufgabe, für die er entwickelt wurde. Ein ASIC ist eine einzigartige Maschine, die von Grund auf neu entwickelt wurde und für deren Aufbau Expertenwissen über Hardware erforderlich ist. ASICs werden häufig beim Kryptowährungs-Mining verwendet, da sie gute Parallelverarbeitungsvorteile und eine bessere Effizienz als GPUs bieten.
Der Hauptunterschied zwischen den beiden besteht jedoch darin, dass GPUs vielseitiger sind. Beispielsweise können Sie mit GPUs ganz einfach ein Kryptowährungs-Mining-Rig bauen. Die Teile sind leicht erhältlich und wenn Sie mit dem Mining fertig sind, können Sie die GPU-Karte jederzeit an Gamer oder andere Miner verkaufen. Bei ASICs kann man jedoch nur eine gebrauchte Maschine an andere Miner verkaufen, weil man damit kaum etwas anderes machen kann.
Jenseits des Kryptowährungs-Mining wird es noch schwieriger, eine ASIC-Maschine in die Hände zu bekommen, da es sich nicht um Massenprodukte handelt. Dies steht in starkem Kontrast zu GPU-Systemen, die Sie überall bekommen und einfach konfigurieren können.
GPU vs. Cluster-Computing
Während eine einzelne GPU-Karte Tausende von Kernen enthält, die jedem Computer, an den Sie sie anschließen, eine enorme Leistung verleihen, können Sie dem Computer-Mainboard theoretisch so viele GPU-Karten hinzufügen, wie es verarbeiten kann, und seine Verarbeitungskapazität weiter erhöhen.
Ein Computercluster hingegen bezieht sich auf mehrere Computer, die miteinander vernetzt sind, um als ein großer Computer – ein Supercomputer – zu fungieren. Jeder Computer im Netzwerk wird als Knoten bezeichnet und kann eine Multi-Core-CPU sowie eine oder mehrere GPU-Karten an Bord haben.
Jeder Cluster muss über einen Master-Knoten verfügen, bei dem es sich um den Frontcomputer handelt, der für die Verwaltung und Planung seiner Worker-Knoten verantwortlich ist. Es wird auch Software enthalten, die Daten und Programme für seine Worker-Knoten zuweist, um Ergebnisse zu berechnen und zurückzugeben.
GPU-Beschleunigung vs. Hyper-Threading
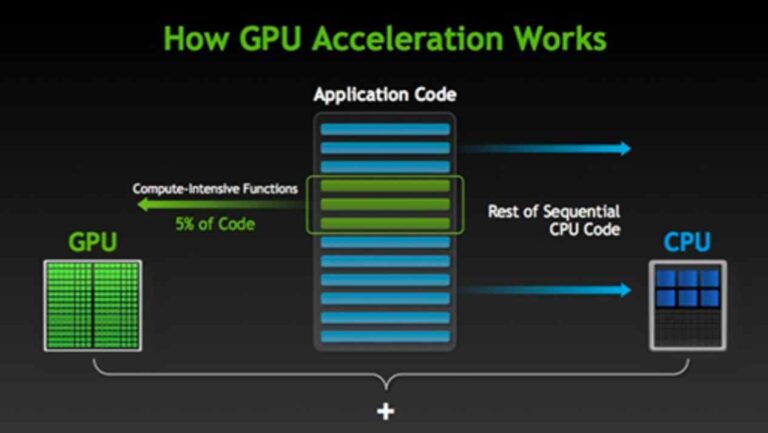
Die CPU ist darauf ausgelegt, mehrere Aufgaben gleichzeitig zu erledigen, und deshalb läuft sie mit sehr hohen Geschwindigkeiten und plant die Verarbeitungszeit zwischen diesen mehreren Prozessen. Wenn es jedoch auf eine rechenintensive Funktion stößt, verbringt es möglicherweise eine Weile in der Schleife, bevor es zu den anderen Prozessen zurückkehrt. Dies führt normalerweise zu einer allgemeinen Verlangsamung des Computers und im schlimmsten Fall zu einem vollständigen Einfrieren des Systems.
Computerdesigner können dieses gefürchtete Szenario vermeiden, indem sie entweder Hyper-Threading oder GPU-Beschleunigung verwenden. Hyper-Threading ermöglicht es einem einzelnen CPU-Kern, als zwei Verarbeitungs-Threads zu fungieren. Wenn also ein Thread in einer rechenintensiven Schleife gefangen ist, kann der andere Thread das System immer noch zusammenhalten.
Moderne Computer haben jetzt mehrere Kerne von 2 bis 4, 8, 16, 32 und so weiter. Außerdem verfügen sie über Hyper-Threading, sodass eine 2-Kern-CPU 4 Threads bietet, eine 4-Kern-CPU 8 Threads und so weiter.
Hyper-Threading mit Mehrkern-CPUs löst die meisten Computerprobleme, verhindert Engpässe und liefert Spitzenleistung bei einfachen Spielen, Musikproduktion und kleinen Grafik-, Video- und maschinellen Lernprojekten. Wenn Sie jedoch mehr Leistung benötigen, ist eine GPU oft die richtige Lösung.
GPU- oder Hardwarebeschleunigung ist die Fähigkeit einer Softwareanwendung, die Parallelverarbeitungsleistung einer GPU zu nutzen, um große Datenmengen zu verarbeiten, ohne die CPU zu verlangsamen. Viele professionelle Anwendungen sind auf die GPU-Beschleunigung angewiesen, um gut zu funktionieren. Dazu gehören Video- und Animationsdesign-/Rendering-Programme, Encoder, Kryptografie, große neuronale Netze und so weiter.
Grundlagen der GPGPU-Programmierung
Die allgemeine Programmierung von GPUs erfolgte ursprünglich mit DirectX und OpenGL Bibliotheken. Diese wurden jedoch ausschließlich für die Grafikentwicklung entwickelt, sodass Sie Ihre Daten in grafikähnliche Modelle umwandeln mussten, um zu funktionieren.
Glücklicherweise gab es im Laufe der Jahre große Fortschritte bei GPGPU, die zu Bibliotheken, Programmiersprachen und Frameworks führten. Das beliebteste dieser Frameworks ist CUDA von Nvidia.
CUDA macht es jedem Entwickler leicht, in die GPU-Programmierung einzutauchen, ohne die Grundlagen der klassischen GPU-Programmierung kennen zu müssen. Es bietet Funktionen, die die Entwicklung über die Grafik hinaus verbessern, wobei viele Einheiten sogar für maschinelles Lernen spezifische Funktionen aufweisen.
Verfügbare Bibliotheken machen es auch einfach, neue GPU-beschleunigte Programme von Grund auf neu zu erstellen oder vorgefertigte an die Parallelverarbeitung anzupassen. Sie wählen die richtige Bibliothek aus, optimieren Ihren Code für parallele Schleifen, kompilieren neu und fertig.
CUDA-Cores vs. Stream-Prozessoren
Oft werden Sie auf die Begriffe stoßen Cuda-Kerne und Stream-Prozessoren. Beide Begriffe beziehen sich einfach auf den GPU-Kern bzw Arithmetische Logikeinheiten einer GPU. CUDA Core ist eine proprietäre Technologie von Nvidia, während Stream-Prozessoren von AMD stammen.
Ein anderer Begriff, auf den Sie vielleicht stoßen, ist Streaming Multi-Processor oder SM. Dies ist eine weitere Nvidia-Technologie, die ursprünglich 8 CUDA-Kerne pro SM gruppierte. Es führt 32-Thread-Warps auf einmal aus und verwendet 4 Taktzyklen pro Befehl. Neuere Designs verfügen jetzt über mehr als 100 Kerne pro Streaming-Multiprozessor.
Top GPU-Sprachen und -Bibliotheken
Es gibt so viele Bibliotheken und Sprachen, die sowohl auf Nvidia CUDA- als auch auf AMD-Plattformen funktionieren. Im Folgenden sind nur einige aufgeführt:
- Nvidia cuBLAS – Grundlegende lineare Algebra-Unterprogramme für CUDA
- cuDNN – Bibliothek für tiefe neuronale Netze
- OpenCL – Offener Standard für parallele Programmierung
- Openmp – Für AMD-GPUs
- HIP – C++-Bibliothek
- Nvidia cuRAND – Generierung von Zufallszahlen
- Manschette – Für schnelle Fourier-Transformation
- Nvidia KKW – 2D-Bild- und Signalverarbeitung
- GPU-VSIPL – Vektorbild- und Signalverarbeitung
- OpenCV – GPU-Bibliothek für Computer Vision
- OpenACC – Sprache für parallele Entwicklung
- PyCUDA – Python für die CUDA-Plattform
- TensorRT – Deep Learning für CUDA
- CUDA-C++ – C++-Sprache für CUDA
- CUDA C – C-Sprache für CUDA
- CUDA Fortran – CUDA für FORTRAN-Entwickler
Top-GPU-Cluster-Projekte
Seit Juni 2022 sind 8 der 10 schnellsten Supercomputer der Welt GPU-beschleunigt. Sie alle teilen sich auch das Linux-Betriebssystem und lauten wie folgt:
| Rang | Name | Petaflops | CPU-Kerne | GPU-Kerne | Leistung (kW) | Jahr |
| 1. | Grenze | 1,102 | 591,872 | 8,138,240 | 21,100 | 2022 |
| 2. | LUMI | 151.90 | 75,264 | 1,034,880 | 2,900 | 2022 |
| 3. | Gipfel | 148.6 | 202,752 | 2,211,840 | 10,096 | 2018 |
| 4. | Sierra | 94.64 | 190,080 | 1,382,400 | 7,438 | 2018 |
| 5. | Perlmutter | 64.59 | N / A | N / A | 2,589 | 2021 |
| 6. | Selene | 63.46 | 71,680 | 483,840 | 2,646 | 2020 |
| 7. | Tianhe-2 | 61.445 | 427,008 | 4,554,752 | 18,482 | 2013 |
| 8. | Ad Astra | 46.1 | 21,632 | 297,440 | 921 | 2022 |
Fazit
Am Ende dieses Tauchgangs zum GPU-Computing und allem, was damit zusammenhängt, sollten Sie sich inzwischen ein Bild von seiner Leistungsfähigkeit und seinem Umfang gemacht haben.
Weitere Informationen finden Sie auf der Entwicklerplattform von NVIDIA hier oder das von AMD hier.

Ähnliche Artikel